非Transformer架构新突破:AI 21 Labs Jamba 1.5系列模型解读
01 Jamba 1.5模型是什么
AI 21 Labs发布了Jamba 1.5系列模型,包括Jamba 1.5 Mini和Jamba 1.5 Large两款模型。Jamba是第一个基于Mamba架构的生产级模型,Mamba是由卡内基梅隆大学和普林斯顿大学的研究人员提出的新架构,被视为Transformer架构的有力挑战者。基于评估,Jamba 1.5拥有最长的有效上下文窗口,在同等大小的所有上下文长度中速度最快,质量得分超过Llama 3.1 70B和405B。
Jamba 1.5系列模型具备四个优势:
✔ 速度快,量化过程只需几分钟;
✔ 不依赖于校准,这一有时不稳定的过程通常需要几个小时或几天;
✔ 仍然可以使用 BF16 来保存大规模激活;
✔ 允许Jamba 1.5 Large适配单个8 GPU节点,同时利用其256K的完整上下文长度。
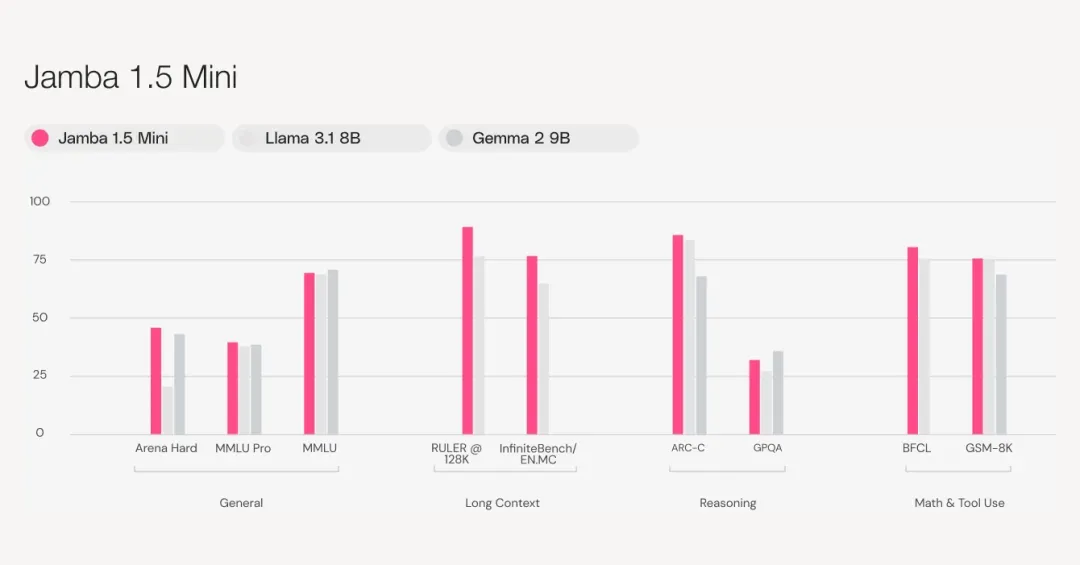
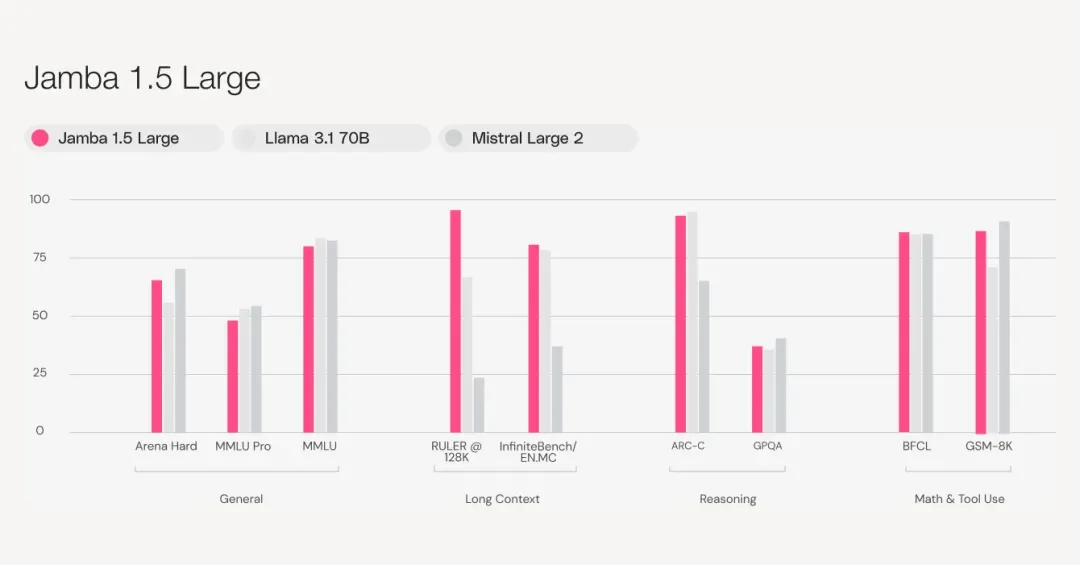
根据Arena Hard基准测试,Jamba 1.5 Mini成为同尺寸级别中最强大的型号,超越了竞争对手Claude 3 Haiku、Mixtral 8x22B和Command-R+。Jamba 1.5 Large同样超越了Claude 3 Opus、Llama 3.1 70B和Llama 3.1 405B等领先型号,在同尺寸级别中具有出色的性价比。
02 Jamba大语言模型在非Transformer架构领域的突破
2024 年 3 月,AI21 Labs宣布推出Jamba,这是世界上第一个基于Mamba架构的模型。Jamba模型是一种创新的混合架构,它结合了Transformer和Mamba模型的优势。Mamba模型是一种结构化的状态空间序列模型(SSM),它通过选择性状态空间来高效捕获序列数据中的复杂依赖关系,并且计算开销随序列长度呈线性增长,这使得它在处理长文本方面比Transformer更加高效。Jamba模型通过交错使用Transformer和Mamba层,不仅继承了Transformer在全局依赖建模上的优势,还吸收了Mamba在处理长序列时的高效性能。
Jamba模型的一个关键特点是它的混合专家(MoE)技术,这允许模型在保持高性能的同时降低资源消耗。MoE通过在模型中引入多个专家模块,选择性地激活部分专家来降低计算复杂度,从而增加模型容量而不显著增加计算需求。
在性能方面,Jamba模型在多个基准测试中展现出了优异的结果,其吞吐量是同等规模Transformer模型的三倍,同时在长上下文处理能力上也有显著提升。Jamba模型支持长达256K个token的上下文长度,这相当于大约210页文本,同时在单个GPU上能够处理高达140K个token的上下文。
1)Transformer的内存占用随上下文长度而变化,内存占用较大;
2)随着上下文的增长,推理速度变慢。
Mamba为语言模型开发开辟了新的可能性,AI21 Labs开发了相应的联合注意力和Mamba (Jamba) 架构,Jamba由Transformer、Mamba和混合专家 (MoE) 层组成,可同时优化内存、吞吐量和性能。
此次发布的Jamba 1.5系列模型基于新颖的 SSM-Transformer 架构构建,具有出色的长上下文处理能力、速度和质量——超越了同尺寸级别的竞争对手,并标志着非 Transformer 模型首次成功扩展到市场领先模型的质量和强度。
此外,Jamba模型还具有一些开发人员友好的特性,如函数调用、结构化JSON输出、文档对象消化和RAG优化等,这些特性使得Jamba在广泛的开发场景中都非常有用。
总的来说,Jamba模型的推出标志着在大型语言模型领域的一个新方向,它通过混合架构和MoE技术,在保持高性能的同时,显著提高了效率和长上下文处理能力,为AI应用开辟了新的可能性。
03 非Transformer模型的未来与发展
许多非Transformer架构是基于Transformer的局限性提出的,比如WKV、Meta的Mega、微软亚研的 Retnet、Mamba、DeepMind团队的Hawk和Griffin 等,大多在原来的RNN基础上,针对Transformer的缺陷和局限性来做改进,因此非Transformer模型与Transformer模型相比,有其独特的优势和特点。
数据来源:公开信息整理,科智咨询,2024年9月
非Transformer模型的特点:
✔ 特定任务优化:非Transformer模型可能针对特定任务进行优化,如语音识别、图像处理等,这些任务可能不需要Transformer模型的长距离依赖捕捉能力。
非Transformer模型的进步:
✔ 新的注意力机制:一些非Transformer模型探索了新的注意力机制,以提高模型的性能和效率;
✔ 创新的网络架构:研究者们不断提出新的网络架构,以解决Transformer模型在某些任务上的局限性。
总而言之,非Transformer模型在一些方面提供了与Transformer模型不同的优势,在资源利用上更为高效,有助于大模型在资源受限环境下的应用,对于推动AI技术的发展具有重要意义。随着研究的不断深入,未来可能会有更多创新的非Transformer模型出现,为大模型的发展带来新的机遇和挑战。